 Doctsf (Modèles & Marques)
Doctsf (Modèles & Marques) Annonces
Annonces
On sent le spécialiste ![]()

sujet bien maitrisé et on sent la précision dans la réponse.
Comment ça, quelques répétitions ? ![]()
meu non, voyons ! ![]()
![]()
![]()
Comment fait-on pour causer avec le chat botté? Faut-il demander une audience?
oui mais attention à l’odeur : " le Chat …G PT "
. ![]()
En gros , un ramassis de conneries
C’est une intelligence artificielle, et certaines des réponses ne sont pas si incohérentes…
Pour des réponses générées par un ordinateur qui ne connait rien à l’électronique, encore moins à tubes, et qui se fonde sur une base de données, ce n’est pas si mal…
L’immense majorité , si !!! , c’est pire que le jeu des sept erreurs ![]()
Bonjour
A mon avis non, c’est simplement un moteur de recherche perfectionné qui va chercher des bribes d’info sur le net et qui les assemble pour fournir un texte qui semble cohérent.
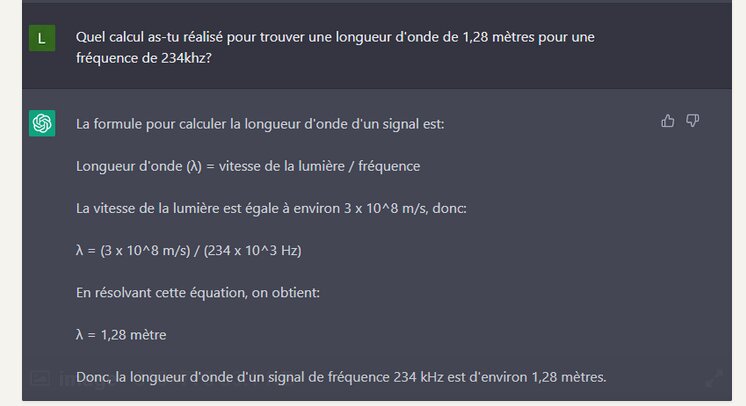
J’ai posé des questions qui étaient plutôt difficiles. L’IA a répondu beaucoup de choses fausses : une parabole de 1.5m est complètement innefficace à 234kHz, ainsi que celle d’Arecibo. Je m’attendais à ce qu’il me donne une parabole de plusieurs km de diamètre, ce qui aurait été bon théoriquement, mais farfelu du point de vue fabrication.
On voit que l’IA a accès à beaucoup d’informations, mais ne sait pas bien les relier entre-elles.
Pour résumer, cette IA donne l’impression de connaître l’électronique et la radio, à la manière de certains personnages beaux-parleurs qu’on peut rencontrer dans la vraie vie.
J’ai un peu insisté au sujet des paraboles. Le résultat est croustillant !
Je me demande d’où sort cette formule. Mes cours d’antenne sont bien loins, mais il me semble que le diamètre doit être d’au moins plusieurs longueurs d’ondes pour être efficace, et non pas lambda/6. De plus, l’IA n’a même pas utilisé sa propre formule pour me répondre 1300m.


Ce n’est pas un moteur de recherche, ni un programme qui consulterait une base de données pour générer une réponse (comme l’aurait fait un humain qui ouvrirait une encyclopédie papier),
chatGPT (avant de le rendre disponible auprès du grand public) est dans un premier temps entraîné à prédire le mot suivant d’un début de phrase,
pour cela un jeu de données immense (issu d’internet, wikipédia, les réseaux sociaux, les articles de presse) est utilisé, c’est ce qu’on appelle l’apprentissage supervisé (dans le sens où ce sont des humains qui ont préparé ce jeu de données), c’est une phase d’apprentissage qui peut durer des semaines,
cette étape sert à ajuster des milliards de paramètres de son réseau de neurones (on peut les voir comme des potards), à chaque fois qu’une erreur de prédiction apparait alors il réajuste ses paramètres, plusieurs algos de minimisation de l’erreur de prédiction existent mais ce serait trop compliqué de les détailler.
Une fois ces potards ajustés de manière définitive : le réseau est prêt à faire ses prédictions sur à peu près n’importe quel thème, il saura générer des suites de mots formant des phrases crédibles, en se basant sur les questions que tu as posées, en prédisant le mot suivant, comme lorsque ton smartphone te suggère un mot lorsque tu commences à taper un SMS, mais chatGPT le fait en mode beaucoup plus puissant, grâce ses milliards de potards dans son réseau, il donne l’illusion de comprendre ce que tu lui demandes et de ne presque jamais se tromper.
Et c’est une méthode de prédiction qui se base sur les maths, en prenant en entrée une phrase transformée en vecteur de nombres, et ensuite chaque potard (des « poids ») modifie le contenu du vecteur, et arrivé à la fin du réseau (en sortie) il obtient un nouveau vecteur, qui après transformation devient le mot probable à ajouter dans la phrase qu’il génère.
Durant ce processus purement mathématique/calculatrice aucune base de données n’est consultée, ce n’est que l’action des « potards » sur les données qui fait qu’en sortie on arrive à obtenir un mot suivant qui colle bien à la phrase en train d’être générée, il y a un coté « boite noire » un peu flippant, avec aucune garantie que ce que raconte le programme est vrai, il peut se contredire d’un paragraphe à un autre, inventer des fakes news sans se démonter, l’utilisateur non expert peut être induit en erreur.
Et en plus cet intelligentissime programme confond tout : diametre de la parabole et demi -onde
et ce qui suit n’est pas mieux ![]()
![]()
![]()
Quelles math?
Du côté des maths, il y a encore pas mal de progrès à faire ![]() :
:
De toute façon, ce chat n’est qu’une machine programmée; sophistiquée peut-être, mais machine quand même!
C’est ce que j’ai fait, mais apparemment, Sa Luminescente Seigneurie est très sollicitée!
C’est sùr, mais le réseau de neurones doit être alimenté par des données d’aprentissage et elles proviennent du net. Donc c’est un moteur de recherche, suivi d’un réseau de neurones qui assemble les données pour leur données une forme cohérente ( ou pas ).
Rien de neuf sous le soleil, les réseaux de neurones existent depuis des lustres.
Le seul atout de ce truc c’est la puissance de calcul.
je dirais la notion de vecteurs (tenseurs) :
c’est avec des vecteurs (ou tenseurs) que les données (texte, image, son) sont représentées, le réseau de neurones manipule que des nombres, il ne comprend pas le concept de texte, image, son, il faut tout représenter en nombres, qu’il manipule ensuite à travers ses réseaux de neurones,
les réseaux de neurones s’appuient aussi sur les concepts de dérivées, de rétro-propagation du gradient, et pas mal de domaines liés aux probabilités, les statistiques, la science des données, le traitement du langage naturel (NLP en anglais) dans le cas de chatGPT,
mais je ne suis pas mathématicien, il y a un PDF intéressant ici :
http://exo7.emath.fr/cours/livre-deepmath.pdf
on peut arriver à comprendre l’idée générale : on entraine un réseau de neurones artificiels avec un jeu de données XXL préparé par des humains (en entrée la donnée, et en sortie la chose qu’on veut que le réseau arrive à prédire, ça peut être un mot, une image, un son), et on espère qu’après lui avoir montré des millions d’exemples le réseau arrive (après beaucoup d’ajustements automatique de ses paramètres grâce à des algos de correction d’erreur durant l’apprentissage) à généraliser, c’est à dire que le réseau puisse prédire des choses même sur des exemples qu’on ne lui a jamais montré,
mais la difficulté si on cherche à comprendre dans le détail c’est que c’est compliqué, ça fait appel à des notions de maths, statistiques, à la science des données, d’architecture de réseau de neurones (chaque année des chercheurs trouvent de nouvelles architectures qui permettent d’améliorer les résultats, parfois de manière spectaculaire).